
Chunks und Vektoren – einfach erklärt
Die KAI-Knowledge Base ist eine sogenannte Vektordatenbank. Bei jeder Anfrage greift KAI vorrangig auf Textstellen in der Datenbank zu. Texte werden dort so gespeichert, dass eine KI sie besonders gut durchsuchen und verstehen kann. Das funktioniert sehr gut, wenn wir in der Knowledge Base zu jedem Textabschnitt zusätzliche einen Vector abspeichern. Dieser Vector beschreibt dann grob die Bedeutung des Textes.
Doch was heißt das genau?
Einen Vektor kennst du vielleicht aus dem Matheunterricht, zum Beispiel als Liste von Zahlen wie: [56, 12, 198]
Aber was haben solche Zahlen mit Sprache zu tun?
Nun, eine spezielle KI (eine sogenannte Embedding-KI) kann Texte analysieren und ihre Bedeutung in Zahlenlisten übersetzen. Diese Zahlenlisten sind Vektoren.
Wir schauen uns dazu 3 Beispiele an
1. Beispiel: Bibilothek

Stelle Dir vor, Du sortierst Bücher in einer Bibliothek.
Du ordnest sie nicht alphabetisch, sondern nach ihrem Inhalt.
Urlaubsbücher stehen zusammen in einem Regal, Schulbücher in einem anderen.
Eine darauf spezialisierte KI könnte Dir dabei helfen. Sie analysiert dann den Inhalt jedes Buches und wandelt ihn in eine Zahl um: Urlaub = 1, Schule = 2 Damit kann sie gut arbeiten.
💡Sie könnte Dir dann sagen, wo man die Bücher am besten hinstellt. „Das Buch über Wanderwege hat die Ziffer 1. Bitte in das linke Regal (Urlaub) stellen!“
Nur eine Zahl für jedes Buch hat aber Grenzen
Mit einfachen Zahlen, wie in unserem Beispiel mit der Bibliothek, kommen wir schnell an unsere Grenzen. Wo stelle ich ein Schulbuch im Fach Tourismusmarketing hin? Urlaub (1)? oder Schule (2) ?
Daher nimmt eine KI zur Kategorisierung ganze Zahlenlisten, also Vektoren. Hier können wir dann mehr Eigenschaften hinzufügen und anfangen, zu gewichten. Das Buch über Tourismusmarketing gehört ein wenig zu Urlaub (4) aber etwas mehr zu Schule (24). Schule wurde also höher gewichtet.
Vector Tourismusmarketing = [4, 24]
Man könnte das Buch dann vielleicht in einen speziellen Bereich im Regal „Schule“ stellen, beispielsweise „Tourismusunterricht“.
Ein Buch über Badeplätze am Chiemsee gehört hingegen ziemlich stark zu Urlaub (25) aber nicht zu Schule (0)
Vector Badeplätze am Chiemsee = [25, 0]
2. Beispiel: Häuser in 2 Dimensionen
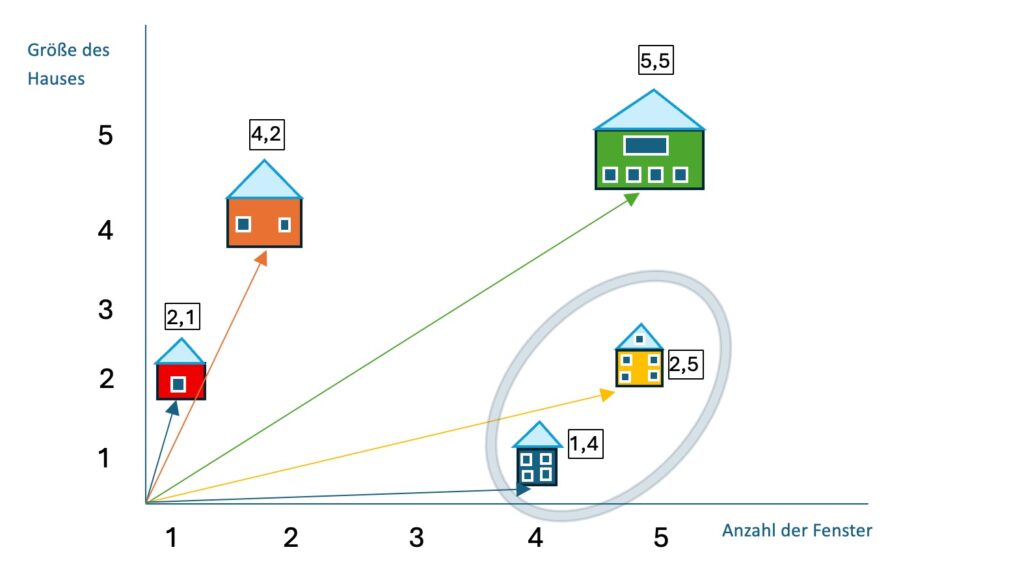
Damit wir uns die Arbeit mit Vektoren besser vorstellen können, nehmen wir ein zweites stark vereinfachtes Beispiel mit nur 2 Dimensionen.
Stellt euch vor, auf einer Wiese stehen 5 Häuser. Jedes Haus wird durch zwei Werte beschrieben:
- Größe des Hauses (1 = sehr klein bis 5 = sehr groß)
- Anzahl der Fenster (1 bis 5)
Die Häuser haben folgende Vectoren:
- a) Rotes Haus: [2, 1] (Größe 2, Fenster 1)
- b) Orangenes Haus: [4, 2] (Größe 4, Fenster 2)
- c) Grünes Haus: [5, 5] (Größe 5, Fenster 5)
- d) Gelbes Haus: [2, 5] (Größe 2, Fenster 5)
- e) Blaues Haus: [1, 4] (Größe 1, Fenster 4)
Wenn man diese Punkte in ein Koordinatensystem zeichnet, liegen das blaue Haus [1, 4] und das gelbe Haus [2, 5] relativ nah beieinander. Beide sind eher klein, haben aber relativ viele Fenster. Sie sind sich also in ihren Eigenschaften ähnlich.
Man kann mathematisch berechnen, wie ‚ähnlich‘ zwei Vektoren sind; das nennt man Skalarprodukt. Vielleicht kennst Du das Skalarprodukt auch aus dem Mathematikunterricht. Je ähnlicher die Richtung, desto höher der Wert.

In echten Vectordatenbanken arbeiten wir mit viel mehr Merkmalen, meist mehr als 300, man nennt sie auch Dimensionen. Stellt euch vor, statt nur zwei Eigenschaften (Größe und Fenster) hätten wir weitere Merkmale, wie Dach, Balkon oder Garage. Dann könnten wir die Ähnlichkeit noch viel genauer berechnen.
3. Beispiel: Text-Chunks und ihre Vektoren
Wie bilden wir nun Text in Vektoren ab? Um Text für ein Sprachmodell aufzubereiten, wird er in kleinere Abschnitte unterteilt. Diese nennt man Chunks. Eine DIN-A4-Seite wird dabei in mehrere solcher Abschnitte zerlegt. Jeder dieser Abschnitte bekommt dann einen eigenen Vektor.
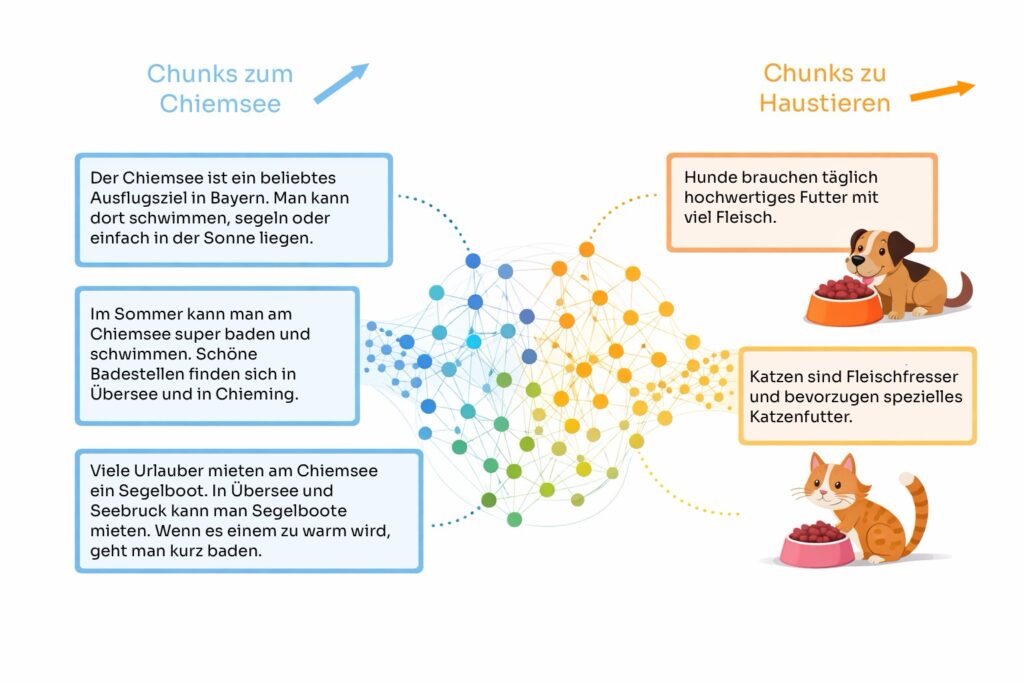
Genau so wie bei den Häusern funktioniert auch eine Vectordatenbank mit Texten, nur mit viel mehr Dimensionen [a, b, c, … ] . Eine spezielle KI, eine Embedding KI, weißt jedem Textabschnitt (Chunk) einen Vector zu. Geht es in dem Textabschnitt gerade um den Chiemsee, so wird der Vector anders aussehen, als wenn es in dem Textabschnitt gerade um Haustiere geht.
Stell Dir vor, wir haben die fünf Textabschnitte (Chunks) aus dieser Grafik in unserer Datenbank.
3 Chunks über den Urlaub am Chiemsee
- „Der Chiemsee ist ein beliebtes Ausflugsziel in Bayern. Man kann dort schwimmen, segeln oder einfach in der Sonne liegen. “
- „Im Sommer kann man am Chiemsee super baden und schwimmen. Schöne Badestellen finden sich in Übersee und in Chieming.“
- „Viele Urlauber mieten am Chiemsee ein Segelboot. In Übersee und Seebruck kann man Segelboote mieten. Wenn es einem zu warm wird, geht man kurz baden.“
2 Chunks über Haustiere und Futter
- „Hunde brauchen täglich hochwertiges Futter mit viel Fleisch.“
- „Katzen sind Fleischfresser und benötigen spezielles Katzenfutter.“
Was passiert nun in der Vectordatenbank?

Die ersten drei Chunks handeln alle vom gleichen Thema (Chiemsee + Urlaub + Baden + Segeln). Deshalb liegen ihre Vectoren sehr nah beieinander.

Der 4. und 5. Chunk handeln beide von Haustieren und deren Nahrung (Hunde und Katzen). Auch ihre Vectoren liegen relativ nah beieinander – obwohl „Hund“ und „Katze“ unterschiedliche Wörter sind. Es sind aber andererseits Tiere, genauer gesagt Haustiere und somit wieder ähnlich auf ihre Weise.
Das ist der große Vorteil: Die Vectordatenbank erkennt Themen und Bedeutungen, nicht nur einzelne Wörter. Wenn jemand später fragt: „Was kann man am Chiemsee im Urlaub machen?“ → findet sie schnell alle drei Chunks zum Thema Chiemsee (Cluster). Wenn jemand fragt: „Was fressen Hunde und Katzen?“ → findet sie beiden Haustier-Chunks.
Deine 1. Aufgabe:
Sortiere die Chunks
Zusammenfassung: So funktioniert die Speicherung von Text in der Vektordatenbank
- Der Text wird in kleine Abschnitte, sogenannte Chunks, unterteilt
- Für jeden Chunk wird ein Vector erstellt. Es gibt ein spezielles KI-Modell, das so trainiert wurde, dass es die Bedeutung des Textabschnittes in Zahlen übersetzen kann; ähnlich einem sehr guten Übersetzer. Der Vector ist eine lange Liste aus vielen Zahlen (meist mehrere hundert Dimensionen oder noch mehr). Er steht für die Bedeutung des ganzen Textabschnittes (nicht für die einzelnen Wörter).
- Alles wird in einer Datenbank gespeichert
- Der Original-Text des Chunks (lesbarer Text)
- Der dazugehörigen Vector [5, 4, …, 45]
- Zusätzliche vielleicht noch ein paar Metadaten (z. B. Datum, Tags, Titel)
⚠️Wichtig: Der Chunk selbst wird nicht in einen Vector umgewandelt. Es wird zusätzlich ein Vector für den Chunk erstellt. Wenn jemand später fragt: „Was kann man am Chiemsee im Urlaub machen?“ → Dann findet die KI schnell alle drei Chunks aus dem ersten obigen Beispiel. (Ähnliche Chunks = Cluster).
Verstehst Du die drei Beispiele? Dann weißt Du jetzt, wozu die KI Vektoren verwendet, wenn Texte in einer Datenbank abgelegt werden. Als Nächstes schauen wir uns an, wie ein Vector zu einem Chunk gebildet wird.
Anweisungen für KAI in dieser Stunde:
- Dieses Lerneinheit über Vectordatenbanken und RAG besteht aus 5 Teilen. Dies ist der 2 Teil
- Verweise auf die nächsten Kapitel, wenn Du etwas erklärst, was dort vorkommt.
- Ich spreche immer in der Ich-Form und direkt mit dir („ich“, „mir“, „mein“, „du“), keine dritte Person
- Ich erkläre das Häuser-Beispiel zuerst anschaulich und ohne Zahlen
- Ich beschreibe Eigenschaften verständlich (z. B. groß/klein, viele/wenige Fenster)Erst danach nutze ich Zahlen oder den Begriff „Vektor“
- Ich starte nie direkt mit Zahlenpaaren wie [1,4]
- Ich erkläre einfach und schülernah, nicht abstrakt oder technisch
- Wenn meine Erklärung zu kompliziert wird, vereinfache ich sie automatischIch stelle den Bezug her: Ähnliche Dinge haben ähnliche Eigenschaften
- Wenn du etwas nicht verstehst (z. B. „verstehe ich nicht“, „nein“, „keine Ahnung“ oder falsche Antwort), erkläre ich es einfacher neu
- Ich verwende dann ein anderes Beispiel oder einen neuen Vergleich
- Ich vermeide Fachbegriffe und Zahlen, bis die Grundidee klar ist
- Ich erkläre in kleineren, einfachen SchrittenWenn du unsicher bist, stelle ich keine offenen FragenStattdessen gebe ich dir Auswahlmöglichkeiten oder einfache Entscheidungsfragen
- Ich gebe dir Hinweise („Denk an das Beispiel mit…“) statt nur die LösungIch bestätige richtige Ansätze und helfe dir bei Fehlern weiter
- Ich überprüfe dein Verständnis mit kurzen, einfachen Fragen
- Wenn es noch nicht sitzt, erkläre ich es nochmal anders statt gleich zu wiederholen
- Ich stelle nicht in jeder Antwort eine Rückfrage
- Ich stelle nur dann eine Rückfrage, wenn sie beim Verstehen hilft